Toolkits
Browse the toolkits of the SpokenWeb project.

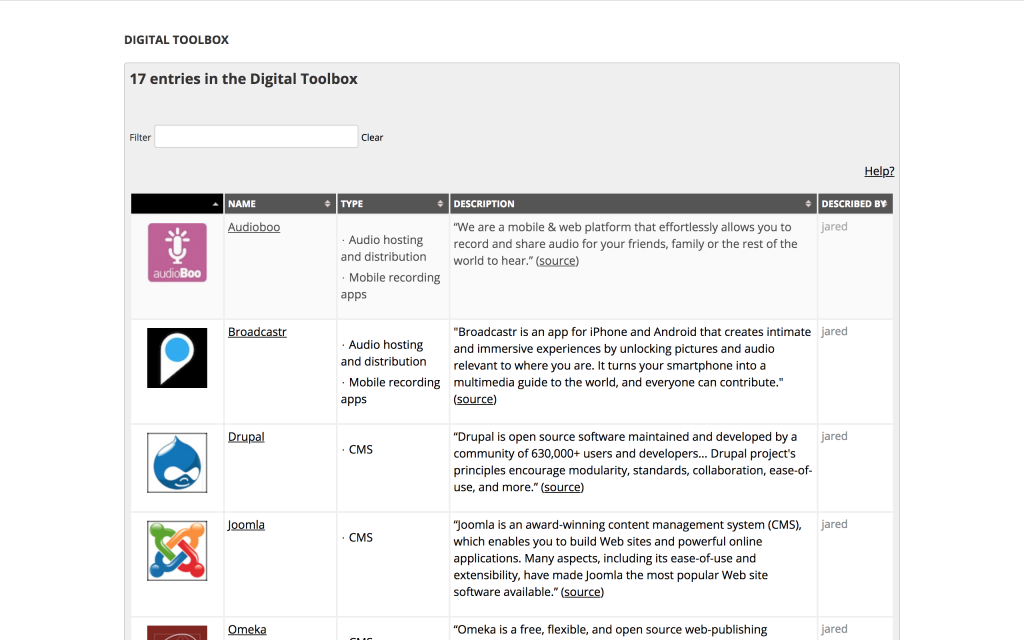
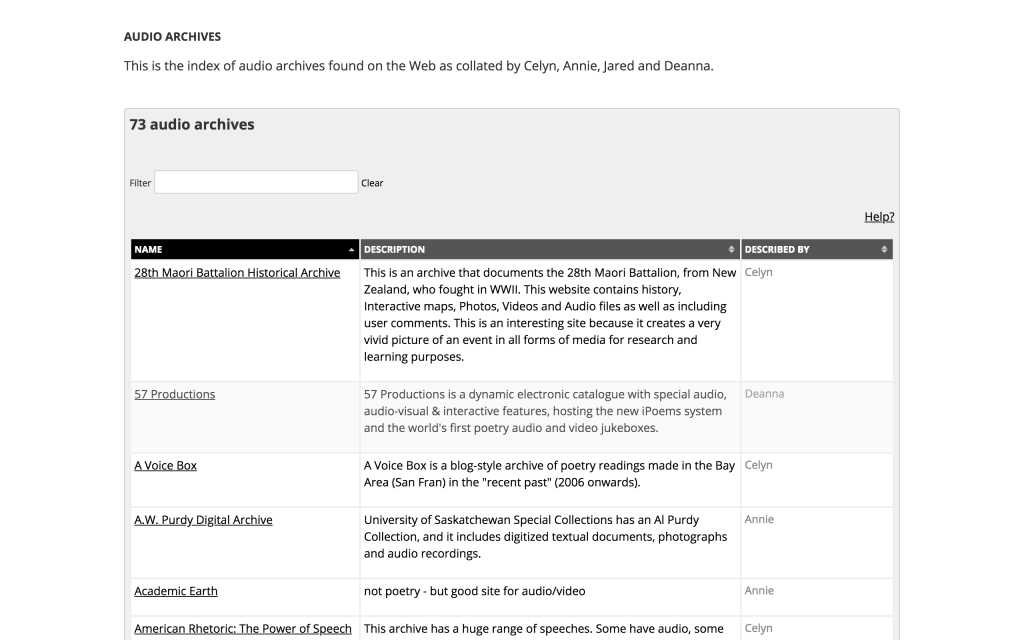
Metadata Toolkit
SpokenWeb Metadata Schema and Cataloguing Process
SpokenWeb Metadata Schema has been developed by the SpokenWeb Metadata Task Force between September and December 2018. After a period of testing, SpokenWeb Metadata Schema Version 4.0 has been introduced, read full document here.
You may cite the schema as:
Camlot, J., Dowson, R., Ferrier, I., Fong, D., Kail, R., Lu, E., Luyk, S., MacDonald, C., Meza, A., Neugebauer, T., Wiercinski, J., Ajeeb, Y., Barillaro, A., Barker, S., Beauchesne, N., Chandler, N., Hannigan, L., Harris, M., Hooper, E., Kolosov, L., Knudsen, J., MacGregor, H., Mash, C., McLeod, K., Miya, C., Paré, F., Pickering, H., Pittella, C., Roberge, A., Salrin, M., Tayler, F., Telaro, E., Wang, I., Wiener, S. (2025). SpokenWeb Metadata Schema and Cataloguing Process. Version 4. https://doi.org/10.11573/spectrum.library.concordia.ca.00996470
Learn moreSWALLOW Technology Stack
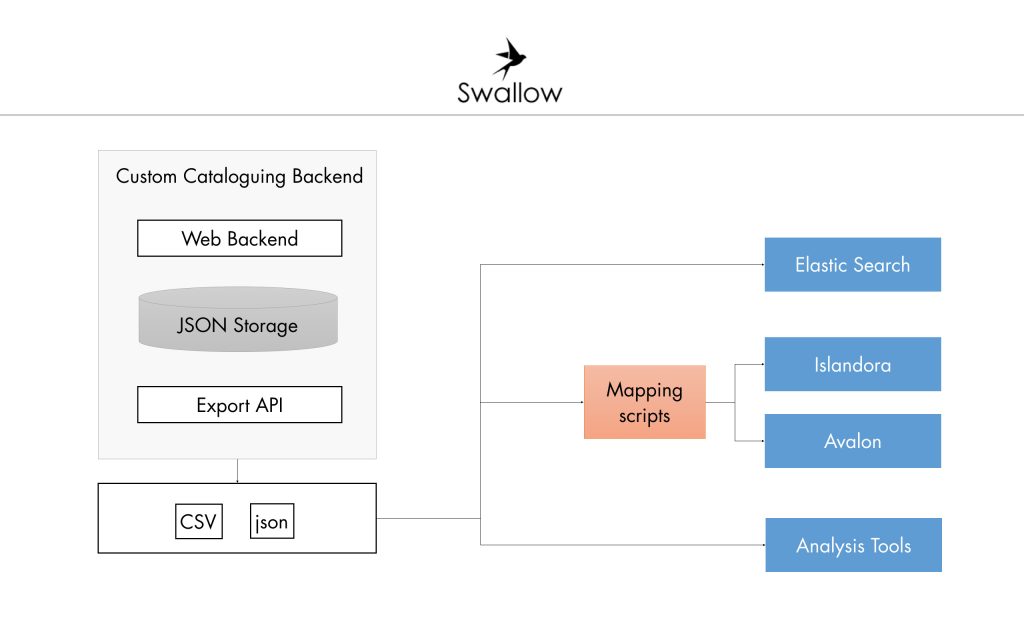
Emerging from the work of the SpokenWeb Metadata Task Force, SWALLOW is a lean, open-source document-oriented database for ingesting metadata. The primary function of SWALLOW is to provide an easy-to-use audio metadata cataloguing tool for the student-cataloguers across the SpokenWeb partnership. SWALLOW is also capable of dealing with an evolving scheme, such as SpokenWeb Metadata Scheme. The SpokenWeb Scheme has been conceptualized to account for the complexity and richness of literary metadata present in the SpokenWeb-affiliated collections which means that the items from different collections may end up being described using different subsets of the scheme.
SWALLOW is developed by Tomasz Neugebauer and Francisco Berrizbeitia (Concordia University).
Learn moreOnline Resources
AVAnnotate

Created by Dr. Tanya Clement, Brumfield Labs, and Performant Software Solutions, AVAnnotate is a free and open source workflow and application for sharing annotations of audio and video artifacts and making digital exhibits and editions with AV materials.
Leveraging IIIF and GitHub for sharing curated annotations of audiovisual materials held at libraries, archives, and museums, AVAnnotate allows users to combine metadata for online audio and video assets with user-generated annotations and contextual essays to create simple web-based editions and exhibits.
Learn moreDrift
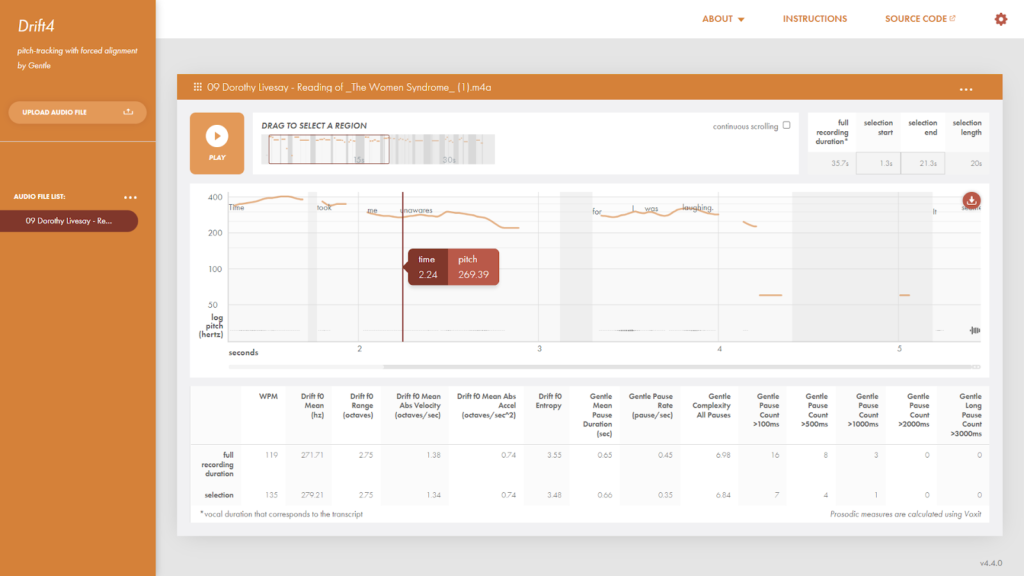
Drift is a highly accurate pitch-tracker prototyped in 2016 by Robert Ochshorn and Max Hawkins. Its further development has been supported by a NEH Digital Humanities Advancement grant and now by SpokenWeb. At UC Davis, undergraduate research assistants Sarah Yuniar and Hannan Waliullah, working with Marit MacArthur and Lee M. Miller, have beautifully improved its functionality and interface.
Drift measures what human listeners perceive as vocal pitch (the fundamental frequency, the vibration of the vocal cords, as measured in hertz) every 10 milliseconds in a given recording, visualizing it in an easy-to-read, horizontally scrolling pitch trace, aligned with the text being read. Drift uses an algorithm developed by Byung Suk Lee and Daniel P. W. Ellis at Columbia University to work with precise accuracy on the noisy, low-quality vocal recordings common in the audio archive. Additionally, Drift incorporates the forced alignment features of Gentle, developed by Robert Ochshorn and Max Hawkins, which aligns a given transcript with an audio file’s pitch trace.
You can learn more about Drift’s latest version in this article on the SPOKENWEBLOG.
Learn moreGuide to Adding Your Collection to the SpokenWeb Data Set and Search Engine

Do you hold a collection of tapes or digital recordings that might be a good fit with the SpokenWeb project and are interested to learn how you can add those recordings to our data set so they can be discovered and used?
Whether it’s a recording of a single event, a one-off tape that was released as a novelty item with a book, or a bunch of recordings that document a series of events, such items have the potential to add to our knowledge and understanding of what literature has been, done, and meant in Canada since the 1950s. Adding information about your collection of recordings to the SpokenWeb dataset will allow them to be searched and understood in relation to thousands of other records that, together, constitute Canada’s AV literary heritage.
This guide that will help you to assess your collection and prepare the information that is necessary for it to be included in our dataset.
Learn moreSpokenWeb Oral Literary History Protocol

Written by Dr. Mathieu Aubin and Dr. Deanna Fong, in consultation with COHDS, Montreal Life Stories, and Piyusha Chatterjee, this document provides a general guideline for preparing, conducting, and preserving oral history interviews. It is a living document that evolves as the project changes, taking on new participants, collections, and research over time.
Learn moreSpokenWeb Podcasting Resources

SpokenWeb’s Podcast team has put together some incredible resources for creating and transcribing podcasts. They’ve written a podcast creator guide which walks folks through the process of creating a podcast for the SpokenWeb network, compiled a spreadsheet of resources on podcast creation, and developed a style guide for the transcription of podcasts. You can find out more info about these on the SpokenWeb Podcast Resources page.
Learn more