A Proposal for Semantic Annotations: An AI-Assisted Approach
November 23, 2021
Francisco Berrizbeitia

Linked data has been a part of Swallow and the SpokenWeb Metadata Schema since its conception. The goal is to be able eventually to expose records in linked data format.¹ We envision that this will make the collections processed by our team more visible in the long term, while allowing novel research opportunities. To achieve our goal for greater linked data,² we need to express the metadata information in the form of triplets:
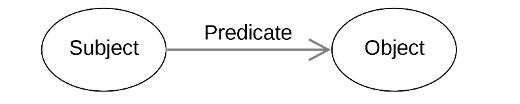
Figure 1 – The basic semantic triple model
CmplstofB, WTFPL, via Wikimedia Commons
Figure 1 shows a general triplet structure: the subject and predicates need to be Unique Resource Identifiers (URIs) and the object can be either an URI, when possible, a literal value or an empty node. In our case the subject of the triplet is the same as the record, say a literary event. The predicate is a property defined in the metadata schema and the object is the value of that property, either defined in a controlled vocabulary file or manually entered by our cataloguers.
A special, more complex case is the contents field, where we first defined a grammar to include Wikidata q-codes of relevant people, places, books, and concepts.³ This process is performed manually by cataloguers, by selecting certain entities and searching for them on the Wikidata.org⁴ search box. The results are very high-quality annotations, but at the expense of the cataloguer’s time.
Given this scenario, we wanted to know if, and to what extent, this process could be automated with the help of a pre-trained Name Entity Recognition (NER) model. The goal was to evaluate the automated method and then make a recommendation. To do this, we compared a manually-tagged dataset (the gold standard) with the results of the automated process. The manually-tagged data set we used was that of the Sir George Williams Poetry Series, consisting of 54 unique entries in Swallow documenting twice as many recorded events, with entries sometimes having as many as 30 or more Wikidata Q codes per unique item content field. This collection was catalogued over the years by Celyn Harding-Jones (full time-stamping and transcription), Faith Paré (editing and corrections), and Ali Barillaro (further editing, reformatting, and the addition of Q codes in square brackets where relevant, throughout the transcription text). Here is an example of what the Q codes look like in the Swallow contents field:
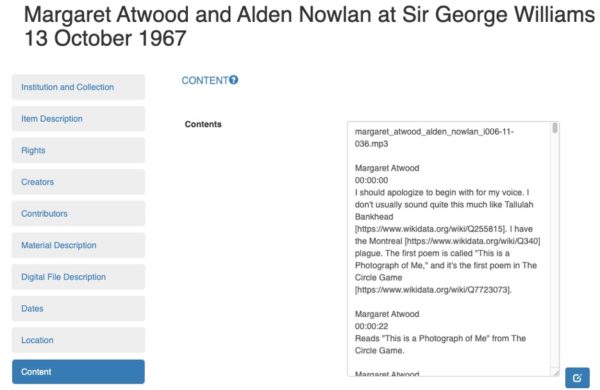
Figure 2 – Wikidata Q codes inserted by cataloguer into Swallow contents description of the SGWU Poetry Series recordings
We ran this comparison between the manually-tagged data set and our automated process results twice, first with the default parameters of the NER tool, and a second time while applying some restrictions we believed could improve the accuracy of the predictions.
The proposed method can be described as follows:
- Preprocessing
- Extract the manually tagged entities from the text.
- Generate a list with the entities (gold standard) and a clean version of the text to be passed to the NER tool.
- Save the results in a new file.
- NER
- Process the clean text using the NER API. This results in a list of dbpedia.org links.⁵
- Access the dbpedia.org link and look for a Wikidata.org equivalent defined via the “sameAs” If one is found, add the Wikidata URL to a list.
- Save the results in a new file.
- Analysis
- Compare both lists and calculate for each record: a) number of entities on the gold standard, b) true positives, c) false positives, d) precision, and e) recall.
- Save the results on a new file.
We decided to use Dbpedia Spotlight⁶ to provide the NER functionality: “DBpedia Spotlight is a tool for automatically annotating mentions of DBpedia resources in text, providing a solution for linking unstructured information sources to the Linked Open Data cloud through DBpedia.”⁷ We favoured this tool because it is an open source, has an easy-to-use API and has previously shown good results.
As has been noted above, the dataset from Swallow used in the experiment was the “SGWU Reading Series-Concordia University Department of English fonds” collection (54 Items). These records all had extensive descriptions in their contents fields, with the substantial number of Wikidata annotations making it ideal for the exercise.
| Default Parameters | Addition of filters | |||||
| True Positives: | 665 | True Positives: | 501 | |||
| False Positive: | 990 | False Positive: | 354 | |||
| Recall: | 0.48 | Recall: | 0.36 | |||
| Precision: | 0.40 | Precision: | 0.59 | |||
Table 1 – Results of the two runs of the experiment
In Table 1, we see the results obtained by the two runs of the exercise. In our opinion, the most relevant result is the precision value, as this number represents how many entities were correctly identified. In our case, around 60% of the entities proposed by the algorithm matched the ones identified by the cataloger. We found this number to be rather low, which motivated us to take a closer look at the false positives in order to identify patterns that could help us further improve the NER configuration. What we found is that quite a few of the false positives were not actually wrong but rather entities that were deemed irrelevant by the cataloguer. This observation made us rethink the “wrongness” of these entities: if we accept the irrelevant entities as true positives, the precision improves to around 80%, albeit on a very small sample size.
We consider these results encouraging enough, not to fully automate the process, but to make useful suggestions that could make the annotation process faster for the cataloguers. We therefore propose a tool that will be accessible from Swallow as a widget for seamless integration within the current workflow. The tool will take the text from the contents field as input and provide an interactive user interface for the cataloger to create annotations. Figure 2 shows the wireframe of the proposed tool, which functions by selecting a category on the tabs panel on the right and clicking the “auto detect entities” button. The software will run the process previously described to create a list of suggested entities for the relevant category. The cataloger will then remove any wrong or irrelevant entities. The tool will also provide a Wikidata lookup functionality to easily add missing entities. The cataloguer will be required to input the entity text—for example by copy and pasting a place or a relevant concept from the contents field—displayed on the left portion of the screen, and the tool will return the matches found on Wikidata, leaving any disambiguation to the human.
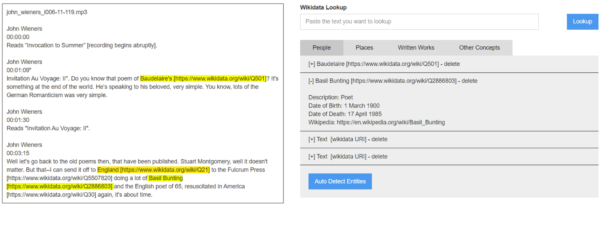 Figure 3- Wireframe of the proposed Swallow widget for semantic annotations
Figure 3- Wireframe of the proposed Swallow widget for semantic annotations
We are hoping that the introduction of this tool will greatly facilitate semantic annotation, thus encouraging the creation of deeply connected datasets. We believe that enhancing the metadata with semantic entities describing the “aboutness” of the items will open up interesting opportunities for the analysis and discovery of SpokenWeb collections by a wide range of researchers, students, and literary practitioners.
References
[1] World Wide Web Consortium, “w3d.org,” [Online]. Available: https://www.w3.org/standards/semanticweb/data#summary.
[2] Wkipedia.org, “Semantic triple,” [Online]. Available: https://en.wikipedia.org/wiki/Semantic_triple. [Accessed 12 10 2021].
[3] SpokenWeb Metadata Task Force, “SpokenWeb Metadata Scheme and Cataloguing Process,” [Online]. Available: https://spokenweb-metadata-scheme.readthedocs.io/en/latest/5-metadata-fields.html#contents. [Accessed 12 10 2021].
[4] D. Vrandečić and M. Krötzsch, “Wikidata: a free collaborative knowledgebase,” Communications of the ACM, vol. 57, pp. 78-85, 2014.
[5] J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer and C. Bizer, “DBpedia – A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia,” Semantic web, vol. 6, pp. 167–195, 2015.
[6] P. Mendes, M. Jakob, A. Garcia-Silva and C. Bizer, “DBpedia spotlight: shedding light on the web of documents,” Proceedings of the 7th international conference on semantic systems, pp. 1-8, 2011.
[7] DBpedia Spotlight, “SPOTLIGHT API,” [Online]. Available: https://www.dbpedia-spotlight.org/api. [Accessed 15 10 2021].
Francisco Berrizbeitia

Francisco Berrizbeitia Eng, M.Sc is a developer at Concordia Library and the lead developer of Swallow. His interests lie in linked open data, text mining, and natural language understanding, currently collaborating with researchers from multiple institutions.